|
|
|
Obtener conjuntos de datos para NLP
PRECAUCIÓN 😱: El tema presentado en esta sección está clasificado como avanzado. El entendimiento de este contenido es totalmente opcional.
Introducción
Obtener un conjunto de datos para tareas de NLP puede ser un tarea compleja dependiendo del problema a realizar. Muchas compañias tienen políticas de adquisición de datos específicas para resolver problemas complejos o muy de nicho. Sin embargo, en muchos casos, la información que necesitamos está disponible, solo que en el formato incorrecto.
Veamos algunas de las formas que tenemos para automatizar la extracción de datos de diferentes origenes:
Extraer texto de imágenes o escaneos
Podemos extraer texto de imagenes aplicandole técnicas de OCR a las mismas. Esta técnica puede ofrecer resultados muy variados dependiendo de la librería o servicio que se utiliza. Proveedores de nube como Google, Microsoft y Amazon AWS ofrecen servicios de OCR de alta performance utilizando modelos del estado-del-arte.
Sin embargo, podemos obtener resultados aceptables utilizando librerias en Python, como pytesseract. Puede instalar esta libreria siguiendo la guía de instalación en la página del autor: https://github.com/madmaze/pytesseract. Los pasos de instalación dependen del sistema operativo que utilice.
En ubuntu:
sudo apt-get install python3-pil tesseract-ocr libtesseract-dev tesseract-ocr-eng tesseract-ocr-script-latn
pip install pytesseract
[ ]:
!sudo apt install python3-pil tesseract-ocr libtesseract-dev tesseract-ocr-eng tesseract-ocr-script-latn
!pip install pytesseract
Descargamos un modelo para la librería pytesseract en español:
[9]:
!mkdir -p ./Models/tessdata
!wget https://github.com/tesseract-ocr/tessdata/raw/main/spa.traineddata \
--quiet --no-clobber --directory-prefix ./Models/tessdata
Configuramos pytesseract para buscar el modelo que descargamos
[17]:
%env TESSDATA_PREFIX=Models/tessdata
env: TESSDATA_PREFIX=Models/tessdata
Para probar el funcionamiento de esta librería, descargaremos una imagen de internet que tiene texto en español:
[23]:
!wget https://s2.favim.com/orig/151226/frases-en-espanol-textos-en-espanol-Favim.com-3808330.jpg -O sample.jpg --quiet
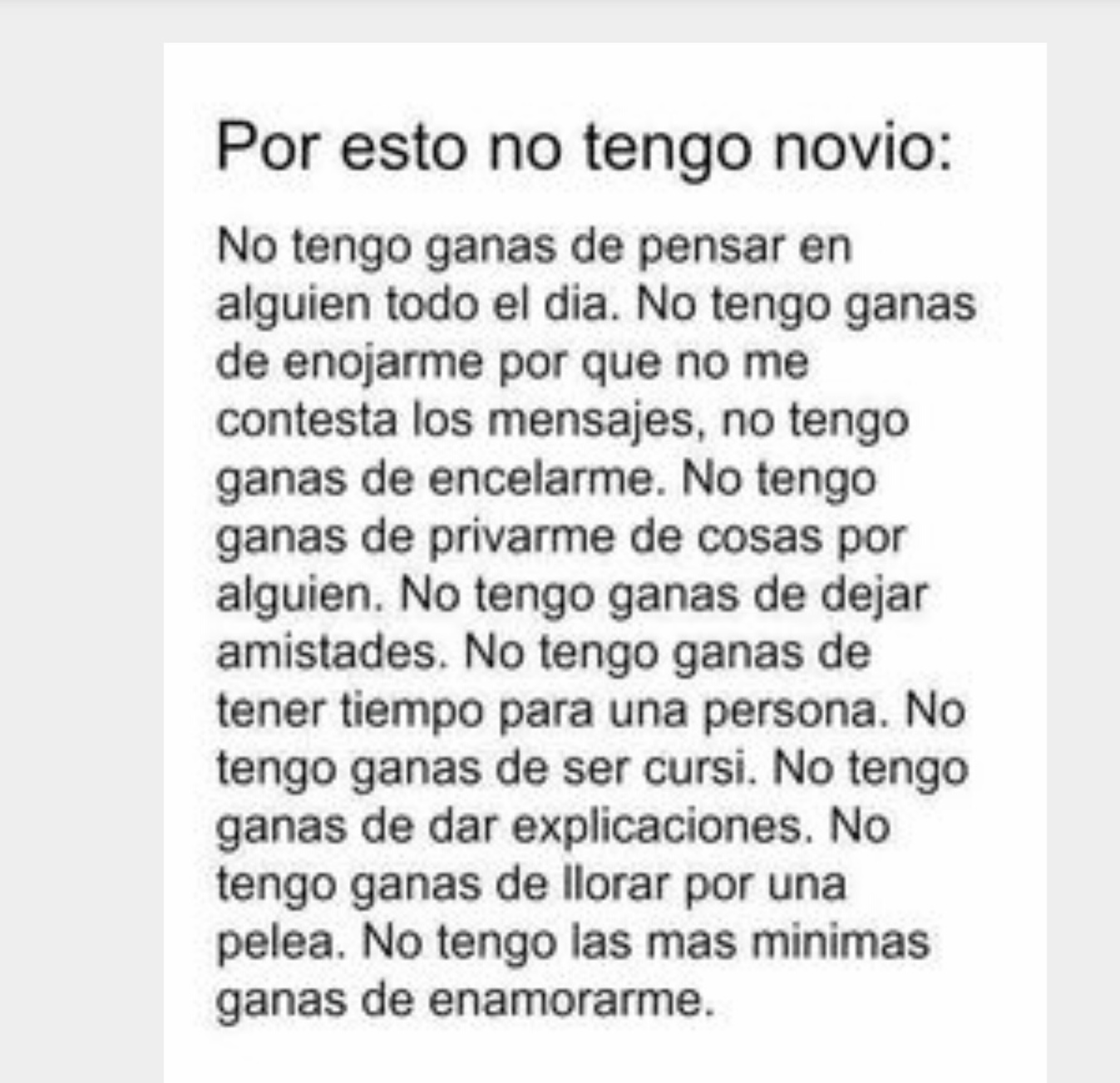
Utilicemos la librería pytesseract para extraer el texto desde este documento:
[19]:
from PIL import Image
from pytesseract import image_to_string
filename = "sample.jpg"
text = image_to_string(Image.open(filename), lang='spa')
print(text)
Por esto no tengo novio:
No tengo ganas de pensar en
alguien todo el dia. No tengo ganas
de enojarme por que no me
contesta los mensajes, no tengo
ganas de encelarme. No tengo
ganas de privarme de cosas por
alguien. No tengo ganas de dejar
amistades. No tengo ganas de
tener tiempo para una persona. No
tengo ganas de ser cursi. No tengo
ganas de dar explicaciones. No
tengo ganas de llorar por una
pelea. No tengo las mas minimas
ganas de enamorarme.
La misma técnica puede utilizarce con archivos PDF
Extraer texto desde la web
Utilizando la libería BeautifulSoap:
pip install bs4
Obtenemos la URL de donde queremos extraer el texto, en este caso son noticias de Google News para Argentina en la categoría Ciencia y Tecnología:
[25]:
url = "https://news.google.com/topics/CAAqLQgKIidDQkFTRndvSkwyMHZNR1ptZHpWbUVnWmxjeTAwTVRrYUFrRlNLQUFQAQ?hl=es-419&gl=AR&ceid=AR%3Aes-419"
Obtenemos el texto:
[26]:
import requests
req = requests.get(url)
web_content = req.text
Extraemos los diferentes títulares. Noten que para hacerlo, debemos indicar la clase del objeto HTML <a> que representa los vínculos a las diferentes noticias. En este caso este valor es «VDXfx». Para saber cual es este valor, puede utilizar la herramienta de desarrolladores de su navegador. En general, accede a la misma con la opción F12:
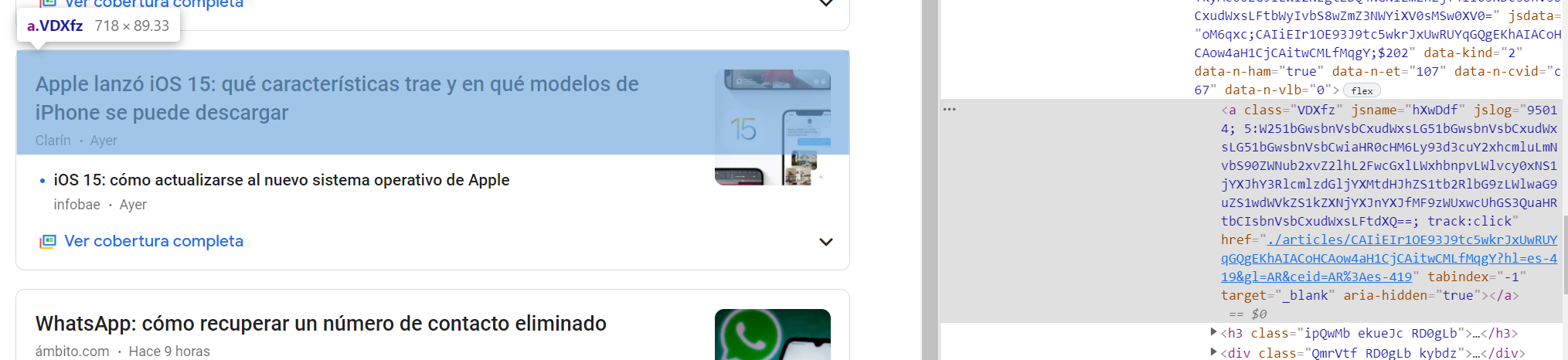
[31]:
from bs4 import BeautifulSoup
soup = BeautifulSoup(web_content,'html.parser')
title = soup.find_all('a', class_='VDXfz')
Obtenemos el link a la primera noticia:
[32]:
first_art_link = title[0]['href'].replace('.','https://news.google.com', 1)
Obtenemos el contenido de la primera noticia:
[35]:
art_request = requests.get(first_art_link)
art_request.encoding='utf8'
soup_art = BeautifulSoup(art_request.text,'html.parser')
art_content = soup_art.find_all('p')
Obtenemos todo el texto de la noticia:
[36]:
art_texts = [p.text for p in art_content]
print(art_texts)
['El pasado 14 de septiembre Apple presentó la nueva generación de su smartphone, el iPhone 13, y aunque no se esperaba un cambio al respecto (al menos no este año), para muchos fue una sorpresa ver que seguía ahí el notch, esa muesca, pestaña, ceja o como quieran llamarla en la parte superior de la pantalla. ¿Cómo puede ser posible en pleno año 2021?', 'Bueno, parece que afortunadamente Apple comenzará a deshacerse del notch el próximo año 2022. Así lo ha asegurado Ming-Chi Kuo, uno de los analistas más conocidos y relevantes en materia de Apple y sus productos. Sin embargo, no serán todos los modelos de iPhone los que por fin se librarán de esa franja negra en sus pantallas, solo los modelos “Pro” y “Pro Max”. Dicho de otro modo, el que por ahora llamaremos iPhone 14 en su versión base o estándar, seguirá teniendo notch.', 'La primera vez que vimos al notch en un iPhone fue en el año 2017, cuando llegó el iPhone X y generación en la que Apple se deshizo del botón de inicio o Home en sus iPhones más actuales, reemplazando el sistema Touch ID (lector de huellas dactilares) por el sistema Face ID que, según la compañía, utiliza una serie de sensores que se encuentran en ese notch. Ahora, 4 años después, el notch ha reducido mínimamente su tamaño, pero sigue ahí y Face ID sigue siendo el método de seguridad por defecto en el iPhone, incluso tras más de un año de muchos usando mascarillas y sin poder desbloquear sus iPhones.', 'Se espera que Apple vuelva a ofrecer Touch ID en modelos futuros del iPhone, ubicando el lector de huellas directamente debajo de la pantalla, pero para eso tendremos que esperar un poco más, posiblemente hasta 2023. Mientras tanto, al menos los próximos iPhone de gama más alta ya no tendrán ese horrible notch sino que lo reemplazarán por un pequeño agujero en la pantalla para la cámara. Esto es, por ahora, solo una filtración, pero una que tarde o temprano se cumplirá sin lugar a dudas. La pregunta es si realmente el notch comenzará a desaparecer en 2022. Ojalá. [vía 9to5Mac]']