|
|
|
BERT: Bidirectional Encoder Representations from Transformers
Introducción
word2vec es un modelo de tipo «context-free», lo que significa que cada palabra recibe un único vector que la representa. Esto implica que por ejemplo la palabra «banco» recibirá la misma representación en las oraciones Los domingos no abre el banco y Estabamos tan cansados que nos sentamos en un banco.
BERT, sin embargo, es un modelo contextual, lo que significa que la representación que se genera de una palabra depende del contexto en el que aparece.
Como funciona
Si recordamos de cuando introducimos word2vec, vimos que las representaciones de las palabras se obtenian al entrenar una red neuronal en una tarea «falsa» que era predecir una palabra dado el contexto en el que aparece. Este contexto lo especificabamos como una ventana de palabras. Los modelos basados en lenguaje, llevan esta tarea un paso más adelante y tratan de predecir la siguiente palabra dada una secuencia de tokens.
En el caso de BERT, está pre-entrenado utilizando 2 tareas distintas:
Masked LM: BERT está basado en una técnica llamada Masked LM (MLM) la cual, en lugar de intentar predecir la siguiente palabra dada una secuencia de palabras, aleatoriamente enmascara palabras en la oración para luego intentar predecirlas desde el contexto. Para hacerlo utiliza el contexto completo de la oración, tanto hacia adelante como hacía atras (por esto se llama bidireccional). En practica, BERT enmascara aproximadamente el 15% de los tokens en una secuencia.
NSP (Next Sentence Prediction): Muchas tareas en NLP requieren el entendimiento de las relaciones entre varias oraciones o secuencias. BERT captura estas relaciones al estar entrenado para predecir la siguiente oración en el cuerpo. En realidad BERT utiliza 50% del tiempo efectivamente la siguiente oración para la tarea de NSP y la taguea con el token IsNext, mientras que el otro 50% utiliza una oración aleatoria del texto y la taguea con el token NoNext.
Para ejecutar este notebook
Para ejecutar este notebook, instale las siguientes librerias:
[1]:
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/NLP/Datasets/mascorpus/tweets_marketing.csv \
--quiet --no-clobber --directory-prefix ./Datasets/mascorpus/
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/docs/nlp/neural/BERT.txt \
--quiet --no-clobber
!pip install -r BERT.txt --quiet
|████████████████████████████████| 3.1 MB 2.1 MB/s
|████████████████████████████████| 831.4 MB 2.5 kB/s
|████████████████████████████████| 163 kB 50.5 MB/s
|████████████████████████████████| 880 kB 57.5 MB/s
|████████████████████████████████| 3.3 MB 46.6 MB/s
Building wheel for sacremoses (setup.py) ... done
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchvision 0.13.1+cu113 requires torch==1.12.1, but you have torch 1.9.0 which is incompatible.
torchtext 0.13.1 requires torch==1.12.1, but you have torch 1.9.0 which is incompatible.
torchaudio 0.12.1+cu113 requires torch==1.12.1, but you have torch 1.9.0 which is incompatible.
[2]:
import warnings
warnings.filterwarnings('ignore')
Cargamos el set de datos
[3]:
import pandas as pd
tweets = pd.read_csv('Datasets/mascorpus/tweets_marketing.csv')
Explorando un modelo pre-entrenado con BERT
Una de las formas más sencillas de trabajar con el modelo BERT es utilizando la libreria transformers de HuggingFace la cual ofrece una forma muy conveniente de acceder a modelos de NLP en diferentes lenguajes e incluso entrenados para tareas especificas.
Podemos instalar esta libreria desde pip de la siguiente forma. Este paso ya lo realizamos en la sección de instalación de este notebook
pip install transformers
Nota: Esta librería ya fué instalada en la preparación del notebook.
BETO: BERT en español
Al igual que con word2vec, entrenar un modelo de lenguaje requiere de una gran cantidad de datos sumado a un poder de computo interesante (cuando BERT fué publicado en 2018, tomó 4 días entrenar el modelo usando 16 TPUs. Si se hubiera entrenado en 8 GPUs hubiera tomado entre 40–70 días).Por este motivo, utilizaremos un modelo pre-entrenado para un cuerpo de texto en español. Este modelo, BETO, fué entrenado sobre un gran corpora de texto. Pueden encontrar más información sobre el autor de este modelo en: https://github.com/dccuchile/beto
Tokenizers
BERT utiliza su propio tokenizer que está basado en WordPiece. Este tokenizer tiene un vocabulario de 30.000 tokens donde cada secuencia comienza con un token especial [CLS]. Exploremos como funciona este tokenizer
[4]:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('dccuchile/bert-base-spanish-wwm-uncased', do_lower_case=True)
Importante: ``AutoTokenizer`` automáticamente detecta el tipo de tokenizer que el modelo require para poder ejecutarse. En este caso, es un ``BertTokenizer``. Puede inspeccionar el tipo de dato que es ``tokenizer`` para verificarlo. Noten que el tokenizer depende del modelo que estamos utilizando.
Exploremos los tokens que genera:
[5]:
text = tweets['TEXTO'][5]
[6]:
text
[6]:
'. @PoliciadeBurgos @PCivilBurgos @Aytoburgos Mismo peligro c/ Rio Viejo junto Mercadona Villimar'
[7]:
tokens = tokenizer.encode(text)
[8]:
tokens
[8]:
[4,
1008,
985,
14666,
1114,
5232,
30958,
985,
9419,
1211,
1123,
5232,
30958,
985,
1457,
1049,
5232,
30958,
1665,
4615,
1013,
989,
10552,
3379,
2689,
2915,
1316,
17400,
24981,
5]
¿Notan algo raro en los tokens generados?
[9]:
tokenizer.decode(tokens)
[9]:
'[CLS]. @ policiadeburgos @ pcivilburgos @ aytoburgos mismo peligro c / rio viejo junto mercadona villimar [SEP]'
¿Siguen notando algo raro?
[10]:
[tokenizer.convert_ids_to_tokens(idx) for idx in tokens]
[10]:
['[CLS]',
'.',
'@',
'policia',
'##de',
'##burgo',
'##s',
'@',
'pc',
'##iv',
'##il',
'##burgo',
'##s',
'@',
'ay',
'##to',
'##burgo',
'##s',
'mismo',
'peligro',
'c',
'/',
'rio',
'viejo',
'junto',
'mercado',
'##na',
'vill',
'##imar',
'[SEP]']
Cargando nuestro modelo de BERT para español
Para cargar nuestro modelo desde el repositorio de modelos de HuggingFace basta con utilizar el método from_pretrained de igual manera que hicimos con el tokenizer. Este método descargará automaticamente el modelo desde el directorio de modelos de HuggingFace. Pueden ver el listado de modelos que están disponibles en este directorio en [https://huggingface.co/models]. Sin embargo, es necesario que indiquemos la tarea que necesitamos resolver para que la libraría pueda generar el objeto
adecuado en Python.
La libraría transformers dispone de varias tareas:
Causal Language Model
Masked Language
Multiple Choice
Next sentence predicción
Question answering
Seq2Seq Language Model
Sequence Classification
Sequence Regression
Token Classification
En nuestro caso, comenzaremos explorando el poder predictivo del modelo y por lo tanto utilizaremos un Masked Language Model, la cual es una de las tareas que BERT fué diseñado especificamente para resolver.
[11]:
from transformers import AutoModelForMaskedLM
model = AutoModelForMaskedLM.from_pretrained('dccuchile/bert-base-spanish-wwm-uncased', return_dict=True)
Notas:
AutoModelForMaskedLMes una utilidad de HuggingFace que permite cargar un modelo de lenguage para la tarea de enmascaramiento de lenguage. Esta clase automaticamente detectará el tipo de modelo que estamos utilizando, en nuestro caso un modelo basado en la arquitectura BERT. El parámetroreturn_dict=Truehará que el modelo retorne un diccionario con los resultados en lugar de un tupla. Esto solo hará que sea más sencillo interpretar los resultados cuando trabajemos más adelante..
Veamos como se comporta nuestro modelo en la tarea de predecir una palabra de un texto:
[12]:
text = "[CLS] Cuando [MASK] contaron lo que sucedia nos quedamos helados. [SEP]"
tokens = tokenizer.tokenize(text)
Noten que el token [MASK] es la palabra que estamos intentando predecir
Necesitamos saber cual de todos los tokens que generamos es exactamente el que enmascaramos:
[15]:
masked_indxs = [idx for idx in range(0, len(tokens)) if tokens[idx] == '[MASK]']
Corremos nuestro modelo:
[16]:
import torch
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
predictions = model(tokens_tensor).logits
Nota: Ejecutar el modelo sobre nuestro texto devolverá diferente cantidad de objetos dependiendo de como se configuró la carga del modelo en el método from_pretrained. En nuestro caso, hemos especificado return_dic=True y por lo tanto la salida del médoto es un diccionario con los resultados (si no lo hubieramos especificado hubiera retornado una tupla). Dentro de lo que nos interesa a nosotros está:
logits: Retorna la secuencia de hidden-states en la última capa del modelo. Esto tiene tamaño (batch_size, sequence_length, hidden_size).
hidden_states: Retorna los hidden-states de todas las capas del modelo. 12 en el caso de BERT. Esta información solo se retorna cuando se indica
output_hidden_states=True
Para más información sobre que objetos se retornan de la ejecución del modelo pueden ver la documentación del modelo BERT: https://huggingface.co/transformers/model_doc/bert.html#bertmodel
Verificamos cuales son las palabras más probables:
[17]:
for i,midx in enumerate(masked_indxs):
idxs = torch.argsort(predictions[0,midx], descending=True)
predicted_token = tokenizer.convert_ids_to_tokens(idxs[:5])
print('Las 5 palabras más probables para la mascara',i,'son:',predicted_token)
Las 5 palabras más probables para la mascara 0 son: ['nos', 'me', 'les', 'le', 'supi']
Explorando las representaciones de BERT
En esta sección exploraremos las representaciones que genera BERT. Como se mencionó, BERT generá representaciones que son dependientes del contexto, algo que lo diferencia de Word2Vec. Esto implica que por ejemplo la palabra «banco» recibirá la misma representación en las oraciones Los domingos no abre el banco y salimos a caminar. Estabamos tan cansados que nos sentamos en un banco a ver gente pasar. Veamos si esto es así como mencionamos explorando estas representaciones
Para hacer esto, volveremos a cargar el modelo, ahora especificando el parametro output_hidden_states=True. Esto hará que el modelo retorne las representaciones de todos los estados intermedios como parte de la salida:
[20]:
model = AutoModelForMaskedLM.from_pretrained('dccuchile/bert-base-spanish-wwm-uncased',
return_dict=True,
output_hidden_states=True)
[21]:
text = "Queriamos retirar dinero del banco. Sin embargo, los domingos el banco no está abierto. Estabamos tan cansados que nos sentamos en un banco a ver gente pasar"
[22]:
indexed_tokens = tokenizer.encode(text)
[23]:
tokens_tensor = torch.tensor([indexed_tokens]) #Al igual que antes, siempre convertimos primero el input en un tensor
hidden_states = model(tokens_tensor).hidden_states
token_embeddings = torch.stack(hidden_states, dim=0) #hidden_states retorna una lista, transformemos esto en un tensor :)
Veamos las dimensiones de este objeto:
[24]:
token_embeddings.shape
[24]:
torch.Size([13, 1, 33, 768])
¿Que significan?
13 es la cantidad de capas dentro del modelo. Si bien BERT posee 12 capas, la capa numero 0 corresponde a los inputs (entradas) del modelo y por eso vemos 13 capas finalmente
1 es la cantidad de muestra en el lote (ie. batch size)
33 es la cantidad de tokens que se inputaron al modelo
768 es la cantidad de unidades de la red neuronal (units) en cada capa
Como nuestro lote/batch solo contiene una oración, podemos deshacernos de la segunda dimensión de este tensor:
[25]:
token_embeddings = torch.squeeze(token_embeddings, dim=1)
token_embeddings.size()
[25]:
torch.Size([13, 33, 768])
Finalmente, para facilitar el entendimiento de la salida, vamos a cambiar el orden de los valores de este tensor. Recordaran que actualmente tenemos un tensor del tamaño (numero_de_capas, numero_de_tokens, features). Para el análisis que queremos realizar, sería mucho más interesante tener algo del tipo (numero_de_tokens, numero_de_capas, features). De esta forma podriamos revisar todas las representaciones de cada token más facilmente:
[26]:
# Cambiamos las dimensiones 0 y 1
token_embeddings = token_embeddings.permute(1,0,2)
token_embeddings.size()
[26]:
torch.Size([33, 13, 768])
¿Entonces cuales son las representaciones?
Las representaciones son tensores del tamaño (12,768). Claramente esto es un gran progreso desde las 100 dimensiones en Word2Vec! Veamos si efectivamente las representaciones de banco son diferentes:
[27]:
for i, token_str in enumerate(indexed_tokens):
print (i, tokenizer.convert_ids_to_tokens(token_str))
0 [CLS]
1 queria
2 ##mos
3 retirar
4 dinero
5 del
6 banco
7 .
8 sin
9 embargo
10 ,
11 los
12 domingos
13 el
14 banco
15 no
16 está
17 abierto
18 .
19 estabamos
20 tan
21 cansados
22 que
23 nos
24 sentamos
25 en
26 un
27 banco
28 a
29 ver
30 gente
31 pasar
32 [SEP]
En este ejemplo tenemos la palabra banco en las posiciones 6, 14 y 27. De estas posiciones, la palabra banco en las posiciones 6 y 14 debería de tener un significado similar, mientra que su versión en la posición 27 debería ser distinta. Para medir esto necesitariamos comparar la similaridad de estas representaciones. Para esto podríamos utilizar una métrica como la Similaridad de coseno (cosine similarity), sin embargo necesitamos contar con un vector unidimensional. Si bien no hay una única forma de resolver este problema, una forma podría ser tomar el promedio de los valores a lo largo de las 13 capas para generar un vector unidimensional por cada token:
[28]:
sentence_embedding = torch.mean(token_embeddings, dim=1)
[29]:
sentence_embedding.shape
[29]:
torch.Size([33, 768])
Computemos ahora las similaridad de las palabras:
[30]:
from scipy.spatial.distance import cosine
(…) retirar dinero delbanco. Sin embargo, los domingos elbancono está abierto (…)
[31]:
1 - cosine(sentence_embedding[6].detach().numpy(), sentence_embedding[14].detach().numpy())
[31]:
0.8966357111930847
(…) retirar dinero delbanco(…) nos sentamos en unbancoa (…)
[32]:
1 - cosine(sentence_embedding[6].detach().numpy(), sentence_embedding[27].detach().numpy())
[32]:
0.7544149160385132
Podemos ver que la similaridad entre cada una de las representaciones es distinta. Tengan en cuenta que este método no es exacto, pero de alguna forma nos da una idea y una intuición de que tan cercanas pueden ser estas representaciones. BERT es un modelo donde las representaciones dependen del contexto y por lo tanto el concepto de «similaridad» aquí es distinto e incluso podría carecer un poco de sentido.
Otra formar de ver las representaciones (de los autores de BERT)
Los autores de BERT proponen una solución un poco distinta, en base a diferentes experimentos que realizaron. Una de las formas que generaron las representaciones con los mejores resultados resultó de concatenar los valores de las últimas 4 capas.
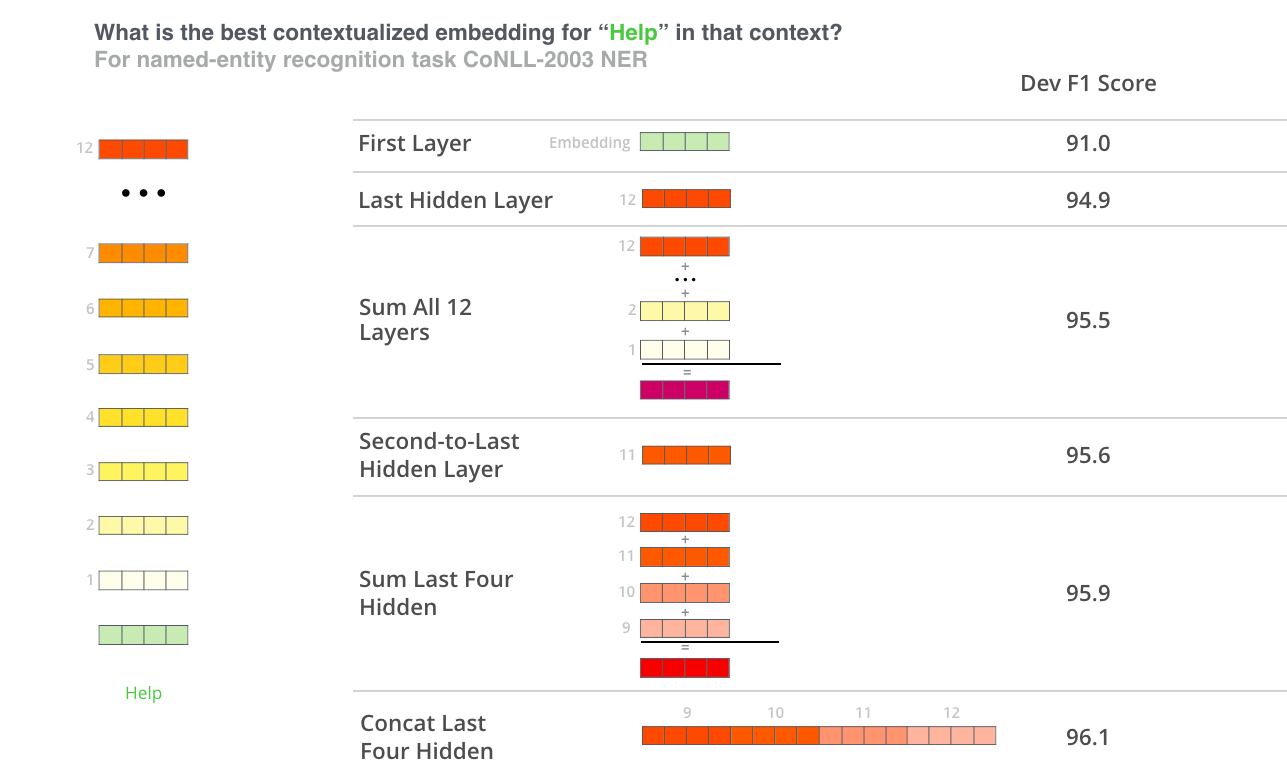
Algo interesante que decanta de este ultimo experimento es que claramente cada uno de las diferentes capas dentro de BERT codifican diferentes aspectos de las palabras y que por lo tanto, la estrategia que mejor se adapta para generar estas representaciones más compactas depende mucho de la tarea que se esté realizando. A continuación intentaremos aplicarlo (noten que en las lineas subsiguientes habrá bastante manipulación de las formas de los vectores)
Nos quedamos con las ultimas capas de cada token:
[33]:
slice_ = token_embeddings.narrow(1, 9, 4)
[34]:
slice_.shape
[34]:
torch.Size([33, 4, 768])
Concatenamos los valores de las últimas 4 capas:
[35]:
concatenated_tensor = slice_.reshape(33, 4*768)
[36]:
concatenated_tensor.shape
[36]:
torch.Size([33, 3072])
Calculamos la similaridad:
[37]:
1 - cosine(concatenated_tensor[6].detach().numpy(), concatenated_tensor[14].detach().numpy())
[37]:
0.8337029814720154
[38]:
1 - cosine(concatenated_tensor[6].detach().numpy(), concatenated_tensor[27].detach().numpy())
[38]:
0.6618704795837402