|
|
|
Explicaciones para NLP utilizando SHAP
Introducción
La idea detrás de los valores de Shapley (Shapley, Lloyd S 1953) es la siguiente: dado un conjunto de predictores, encontrar la contribución marginal de cada predictor con respecto a la predicción general. ¿cuál es la predicción general? Es el valor esperado del modelo (EV). Piense en ello como la línea de base del modelo. Entonces, la contribución marginal indica en que medida cada predictor obliga a la predicción a alejarse de esa línea de base.
Para una introducción más detallada puede ver la entrada del blog: Model interpretability — Making your model confesses: SHAP
¿Como funciona?
La forma en que los valores de Sharpley calculan la contribución marginal es calculando el valor predicho con y sin el valor de la característica que se está considerando actualmente y tomando la diferencia para obtener la contribución marginal. Finalmente, el valor de Sharpley se calcula promediando la contribución marginal del valor de la característica en todos los subconjuntos de características posibles (llamados coaliciones) dentro del conjunto de características en el que participa la característica.
Este algorimo se encuentra implementado en la libraria Shap. Para mas información sobre esta librería visite: https://shap.readthedocs.io/en/latest/index.html
Para ejecutar este notebook
[1]:
import warnings
warnings.filterwarnings('ignore')
Para ejecutar este notebook, instale las siguientes librerias:
[2]:
!pip install transformers --quiet
!pip install shap --quiet
|████████████████████████████████| 4.9 MB 5.2 MB/s
|████████████████████████████████| 163 kB 36.1 MB/s
|████████████████████████████████| 6.6 MB 36.2 MB/s
|████████████████████████████████| 569 kB 5.0 MB/s
Cargamos el conjunto de datos con el que se entrenó el modelo en caso de necesitarlo
[3]:
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/NLP/Datasets/mascorpus/tweets_marketing.csv \
--quiet --no-clobber --directory-prefix ./Datasets/mascorpus/
[4]:
import pandas as pd
tweets = pd.read_csv('Datasets/mascorpus/tweets_marketing.csv')
Cargando un modelo de NLP
Recordemos que nuestro modelo predice los sectores a los que pertenecería el tweet, siendo ellos:
[5]:
target_names = {0:'ALIMENTACION', 1:'AUTOMOCION', 2:'BANCA', 3:'BEBIDAS', 4:'DEPORTES', 5:'RETAIL', 6:'TELCO'}
Cargaremos el modelo que fue descargado anteriornmente utilizando la librería de transformers. Note que cargamos tanto el tokenizer como el modelo propiamente dicho.
Nota: Utilizaremos un modelo entrenado para resolver el problema de tweets que venimos viendo en este curso. Este modelo fue publicado en el repositorio de HuggingFace bajo el nombre
fce-m72109/mascorpus-bert-classifier.
[6]:
import transformers
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "fce-m72109/mascorpus-bert-classifier"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name,
id2label=target_names,
label2id={v:k for k,v in target_names.items()})
Tip: Agregar los parameteros
id2labelylabel2idpermite que el modelo pueda conocer los verdaderos valores de las clases que predice.
Construimos un pipeline con nuestro modelo y tokenizer
[7]:
pred = transformers.pipeline("text-classification", model=model, tokenizer=tokenizer, device=-1, top_k=1)
Generando explicaciones con SHAP
[8]:
sample = ["Nos estafaron en carrefour. No vuelvo a comprar alli jamas"]
[9]:
import shap
explainer = shap.Explainer(pred)
shap_values = explainer(sample)
Partition explainer: 2it [00:31, 31.69s/it]
Visualizando las explicaciones
[10]:
shap.plots.text(shap_values)
Podemos analizar el impacto de una sola clase:
[11]:
shap.plots.text(shap_values[:, :, "ALIMENTACION"])
Visualizando las palabras que tienen el mayor impacto en una clase determinada:
[12]:
shap.plots.bar(shap_values[:,:,"ALIMENTACION"][0])
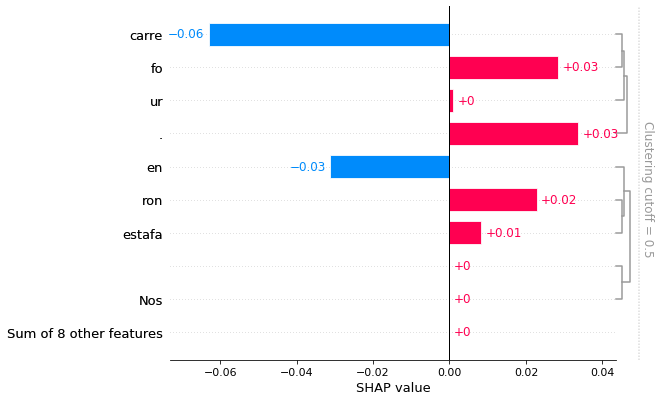
En los ejemplos anteriores, explicamos la salida directa del objeto pipline, que son las probabilidades de clase. A veces tiene más sentido trabajar en un espacio de probabilidades logarítmicas donde es natural sumar y restar efectos (la suma y la resta corresponden a la suma o resta de bits de información de evidencia).
[13]:
logit_explainer = shap.Explainer(shap.models.TransformersPipeline(pred, rescale_to_logits=True))
logit_shap_values = logit_explainer(sample)
shap.plots.text(logit_shap_values)
Partition explainer: 2it [00:26, 26.26s/it]