Videos como secuencias
Un video es, en esencia, una secuencia de cuadros o frames que se transicionan entre si a una determinada velocidad. Por ejemplo, un video tipico de los que puede ver en internet muestran 24 cuadros por cada segundo. Es decir, transicionan 24 imagenes en cada segundo de tiempo. Una forma sencilla de aplicar los conceptos que vimos hasta ahora es intentar aplicar una red CNN a cada cuadro del video, para luego tomar algún tipo de promedio cada X cantidad de tiempo. Aunque esto produciría un resultado, este modelo carecería de la habilidad de diferenciar que existen momentos más importantes que otros durante el video. EL promedio simplemente licuaría esa realidad.
Para evitar este problema, podemos utilizar los conceptos de redes recurrentes para modelar secuencias, tales como las vimos en Redes Neurales Recurrentes. Esta arquitectura, nos permitiría combinar los atributos de cada cuadro del video para podrucir resultados más significativos.
Combinando CNNs con RNNs
Vimos que la arquitectura de CNN era muy útil para trabajar con la forma en la que se alamacenan las imágenes. Por esto, resulta atractiva la idea de combinar las bondades de las redes convolucionales con la capacidad de manejar secuencias de las redes recurrentes. Para realizarlo, en lugar de conectar la entrada de la red recurrente directamente a los pixeles de las imagenes, podemos conectarlas a las representaciones que son generadas por las capas de convolución.
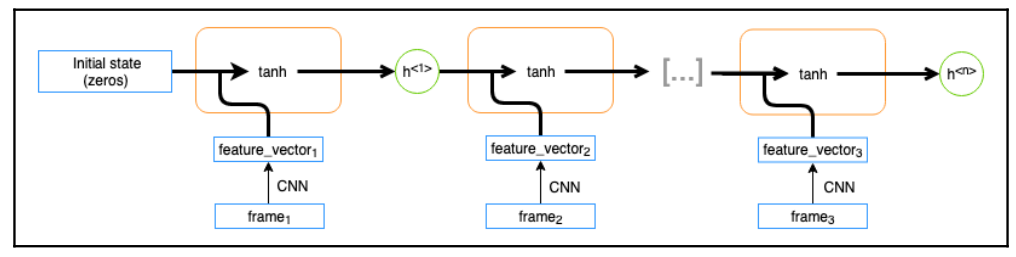
Arquitectura genérica de una red RNN con vectores de características de CNN
Cantidad de cuadros
Como se mencionó, un video puede ser defragmentado en una secuencia de cuadros que se transicionan en el tiempo. Sin embargo, descomponer un video de tal forma puede dar lugar a estructuras de datos másivas. Considere un video de 30 segundos, a 24 cuadros tendriamos secuencias de 720 pasos. Vimos que modelos como BERT están limitados en las longitudes de secuencias con valores muchos más chicos, por lo que esto se volverá un problema rápidamente.
Muestreo o sampling
Este problema no es nuevo de aprendizaje automático, sino que todas las técnicas de procesamiento de video se han encontrado con esta realidad y en general se soluciona utilizando alguna técnica de muestreo o sampling. Si bien esta técnica funciona, rápidamente se dará cuanta que esta técnica podría estar perdiendo información importante para la tarea que se quiere resolver.
Detección de escena
Una técnica más avanzada para realizar esto es utilizar scene extraction o extracción de escenas. Se trata de una técnica muy popular, sobre todo cuando queremos analizár videos de larga duración, donde un algoritmo detecta cuando el video ha cambiado de una escena a la otra. Por ejemplo, cuando la camara enfoca a otro lugar, o cuando se acerca a una escena en particular, etc. Por cada una de estas escenas, podríamos tomar una muestra de un cuadro para utilizar como entrada en nuestra secuencia.
Estos algoritmos hoy en día resultan sumamente eficientes y pueden computar estos cambios de escenas de forma rápida utilizando las variaciones de colores en los pixeles de cada uno de los cuadros.