|
|
|
Ejemplo: Modelo Generator con Keras
PRECAUCIÓN 😱: El tema presentado en esta sección está clasificado como avanzado. El entendimiento de este contenido es totalmente opcional.
Introducción
Una de las formás más sencillas de utilizar esta idea es simplemente utilizando el vector resultante de la red RNN. De esta forma al modelo observa el estado final al que ha arrivado la red y toma una decisión dependiendo del caso a resolver. Tipicamente este vector resultante es conectado a una capa densa (fully connected layer) para general la predicción. Los grandientes de los errores son propagados en la red para toda la secuencia y suele ser cualquier función típica como ser
cross entropy, hinge, etc.
Veremos como podemos aplicar esta idea para crear un generador de tweets.
Para ejecutar este notebook
Para ejecutar este notebook, instale las siguientes librerias:
[ ]:
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/NLP/Datasets/mascorpus/tweets_marketing.csv \
--quiet --no-clobber --directory-prefix ./Datasets/mascorpus/
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/NLP/Utils/TextNormalizer.py \
--quiet --no-clobber --directory-prefix ./Utils/
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/NLP/Utils/PadSequenceTransformer.py \
--quiet --no-clobber --directory-prefix ./Utils/
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/docs/nlp/neural/sequences-generator.txt \
--quiet --no-clobber
!pip install -r sequences-generator.txt --quiet
Descargamos nuestros vectores de word2vec en español
[ ]:
!mkdir -p ./Models/Word2Vec
!wget https://santiagxf.blob.core.windows.net/public/Word2Vec/model-es.bin \
--quiet --no-clobber --directory-prefix ./Models/Word2Vec
[ ]:
import warnings
warnings.filterwarnings('ignore')
Instalamos las librerias necesarias
[ ]:
!python -m spacy download es_core_news_sm 1> /dev/null
Cargamos el set de datos
[ ]:
import pandas as pd
tweets = pd.read_csv('Datasets/mascorpus/tweets_marketing.csv')
[ ]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(tweets['TEXTO'], tweets['SECTOR'],
test_size=0.33,
stratify=tweets['SECTOR'])
Preprocesamiento de texto
Al igual que con Topic Modeling, nuestro primer paso es preprocesar el texto. Para focalizarnos en Word2Vec en este modulo, les preparé un modulo TweetTextNormalizer que hará todo el preprocesamiento por nosotros. Pueden explorar los parametros que recibe el constructor de esta clase para ver que opciones podemos configurar como Stemmer, Lemmatization, etc.
En lo particular, estamos creando un TweetTextNormalizer que:
Aplicará un tokenizer especifico para Twitter
Eliminará URLs
Eliminará acentos
Eliminará las mayusculas
Adicionalmente, el parametro text_to_sequence=True indica que la salida de este proceso no serán oraciones sino que tokens.
[ ]:
from Utils.TextNormalizer import TweetTextNormalizer
[ ]:
normalizer = TweetTextNormalizer(preserve_case=False,
strip_stopwords=False,
lemmatize = False,
text_to_sequence=True,
token_min_len=0)
Podemos probar como funciona:
[ ]:
normalized_tweets = list(normalizer.transform(tweets["TEXTO"]))
[ ]:
normalized_tweets[50]
['el', 'jazz', 'de', 'carrefour', 'es', 'muy', 'bueno', '.']
Vectorización de las palabras
En las actividades anteriores utilizamos siempre un TF-IDF vectorizer para generar los vectores. En esta oportunidad utilizaremos vectores densos. Aprenderemos estos vectores densos como parte de la red que estamos entrenando.
Por este motivo, realizaremos una vectorización utilizando index-based encoding.
[ ]:
from tensorflow.keras.preprocessing.text import Tokenizer
[ ]:
BOS = "/bos"
EOS = "/eos"
[ ]:
tokenizer = Tokenizer(oov_token="[UNK]", filters='!"#$%&()*+,-.:;<=>?@[\\]^_`{|}~\t\n')
tokenizer.fit_on_texts(normalized_tweets)
tokenizer.fit_on_texts([BOS])
tokenizer.fit_on_texts([EOS])
Verifiquemos el vocabulario resultante:
[ ]:
vocab_size = len(tokenizer.word_index) + 1 # OOV
print('El tamaño del vocabulario es: %d' % vocab_size)
El tamaño del vocabulario es: 9999
Veamos algunos de los vectores resultantes:
[ ]:
list(tokenizer.word_index.items())[:20]
[('[UNK]', 1),
('de', 2),
(',', 3),
('.', 4),
('la', 5),
('y', 6),
('en', 7),
('que', 8),
('', 9),
('el', 10),
('a', 11),
('...', 12),
('!', 13),
('?', 14),
('un', 15),
('no', 16),
('me', 17),
('con', 18),
('para', 19),
('una', 20)]
[ ]:
tokenizer.texts_to_sequences(["/eos"])
[[9998]]
Aplicamos la transformación para pasar de palabras a indices:
[ ]:
encoder_tweets = list()
decoder_tweets = list()
target_tweets = list()
[ ]:
for tweet in normalized_tweets:
tweet_enc = tweet.copy()
tweet_dec = tweet.copy()
tweet_tar = tweet.copy()
tweet_enc.insert(0, BOS)
tweet_dec.insert(0, BOS)
tweet_enc.append(EOS)
tweet_dec.append(EOS)
tweet_tar.append(EOS)
encoder_tweets.append(tweet_enc)
decoder_tweets.append(tweet_dec)
target_tweets.append(tweet_tar)
[ ]:
encoder_tweets[0]
['/bos', '#tablondeanuncios', 'funda', 'nordica', 'ikea', '#madrid', '/eos']
[ ]:
decoder_tweets[0]
['/bos', '#tablondeanuncios', 'funda', 'nordica', 'ikea', '#madrid', '/eos']
[ ]:
target_tweets[0]
['#tablondeanuncios', 'funda', 'nordica', 'ikea', '#madrid', '/eos']
[ ]:
input_encoder = tokenizer.texts_to_sequences(encoder_tweets)
input_decoder = tokenizer.texts_to_sequences(decoder_tweets)
target_decoder = tokenizer.texts_to_sequences(target_tweets)
[ ]:
from Utils.Word2VecVectorizer import Word2VecVectorizer
w2v = Word2VecVectorizer(model_path='Models/Word2Vec/model-es.bin', sequence_to_idx=False)
[ ]:
topics = tweets["SECTOR"].to_numpy().reshape(-1, 1)
[ ]:
topic_decoder = list(w2v.transform(topics))
[ ]:
import numpy as np
topic_decoder_np = np.asarray(topic_decoder).reshape(-1, 100)
[ ]:
topic_decoder_np.shape
(3763, 100)
Construirmos un modelo basado en secuencias
Ajustando la longitud de las secuencias
Los modelos basados en secuencias pueden adaptarse a cualquier longitud de secuencia, sin embargo, los parametros de nuestras redes neuronales deberan ser fijos. Para esto definiermos una longitud máxima de la secuencia que vamos analizar. Para esto podemos utilizar un valor especifico o utilizar el valor máximo de tokens que hay en nuestro corpus.
Para saber que valor es el correcto, podemos graficar la distribución de cantidad de palabras en los tweets:
[ ]:
tweets_lens = [len(n) for n in input_encoder]
tweets_lens
import seaborn as sns
sns.displot(tweets_lens)
<seaborn.axisgrid.FacetGrid at 0x7f557270ed90>
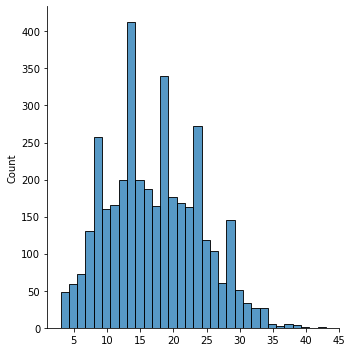
Utilicemos entonces:
[ ]:
max_seq_len = 50
La siguiente clase PadSequenceTransformer es un modulo que les preparé para simplificar este procesamiento. El mismo se encarga de ajustar cualquier secuencia para que tenga exactamente max_seq_len. Cuando la lingitud es mejor, se completan con ceros.
[ ]:
from Utils.PadSequenceTransformer import PadSequenceTransformer
[ ]:
padder = PadSequenceTransformer(max_len=max_seq_len, padding='post')
[ ]:
input_encoder_padded = padder.transform(input_encoder)
input_decoder_padded = padder.transform(input_decoder)
target_decoder_padded = padder.transform(target_decoder)
Convertimos nuestra entrada a arreglos de tipo numpy
[ ]:
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
label_encoder = label_encoder.fit(tweets["SECTOR"])
number_classes = len(label_encoder.classes_)
[ ]:
import numpy as np
input_encoder_np = np.array(input_encoder_padded).astype('int32')
input_decoder_np = np.array(input_decoder_padded).astype('int32')
target_decoder_np = np.array(target_decoder_padded).astype('int32')
[ ]:
topic_decoder = label_encoder.transform(tweets["SECTOR"])
[ ]:
import tensorflow.keras as keras
topic_decoder_np = keras.utils.to_categorical(topic_decoder).astype('int32')
[ ]:
topic_decoder_np.shape
(3763, 7)
Creando conjuntos de entrenamiento y validación
Crearemos 2 conjuntos de datos para entrenar y validar
[ ]:
from sklearn.model_selection import train_test_split
idx_train, idx_test = train_test_split(range(len(input_encoder_np)),
test_size=0.33,
stratify=tweets['SECTOR'])
Necesitamos la variable de salida codificada también en forma de indices:
Creamos los conjuntos de datos:
[ ]:
from tensorflow.keras.utils import to_categorical
input_encoder_train = to_categorical(np.array(input_encoder_np[idx_train]), num_classes=vocab_size)
input_decoder_train = to_categorical(np.array(input_decoder_np[idx_train]), num_classes=vocab_size)
target_decoder_train = to_categorical(np.array(target_decoder_np[idx_train]), num_classes=vocab_size)
#input_decoder_train = np.array(label_encoder.transform(tweets["SECTOR"][idx_train]))
input_encoder_test = to_categorical(np.array(input_encoder_np[idx_test]), num_classes=vocab_size)
input_decoder_test = to_categorical(np.array(input_decoder_np[idx_test]), num_classes=vocab_size)
target_decoder_test = np.array(input_decoder_np[idx_test]), num_classes=vocab_size)
#input_decoder_test = np.array(label_encoder.transform(tweets["SECTOR"][idx_test]))
[ ]:
print("TRAIN")
print("input_encoder_train:", input_encoder_train.shape)
print("target_decoder_train:", target_decoder_train.shape)
print("input_decoder_train:", input_decoder_train.shape)
print("\nTEST")
print("input_encoder_test:", input_encoder_test.shape)
print("target_decoder_test:", target_decoder_test.shape)
print("input_decoder_test:", input_decoder_test.shape)
TRAIN
input_encoder_train: (2521, 50, 9999)
target_decoder_train: (2521, 50, 9999)
input_decoder_train: (2521, 50, 9999)
TEST
input_encoder_test: (1242, 50, 9999)
target_decoder_test: (1242, 50, 9999)
input_decoder_test: (1242, 50, 9999)
Construyendo el modelo
Para construir nuestro modelo, utilizaremos TensorFlow. En particular utilizaremos la API de Keras que nos permite componer modelos de redes neuronales como una secuencia de pasos o capas que se conectan en una dirección.
Utilizemos los siguientes tipos de capas:
Embedding: Esta capa transforma vectores que representan indices dentro de una matriz en representaciones vectoriales densas. Básicamente en este caso nos resolverá la busqueda de las representaciones vectoriales para nuestras palabras. Intentaremos aprender embdeddings de tamaño 100
SpatialDropout1D: Este tipo de capas ayudan a promover la independencia entre filtros (feature maps). Funciona en forma analoga a Dropout pero en lugar de desconectar elementos individuales, desconecta el filtro completo.
LSTM: Long Short-Term Memory layer - Hochreiter 1997
Dense: Una típica capa de una red neuronal completamente conectada (fully connected)
Algunos detalles para notar:
loss=”sparse_categorical_crossentropy”, este problema de clasificación (crossentropy) de más de una clase (categorical). Sin embargo, nuestro output produce probabilidades de cada una de las clases posibles (7) en forma one-hot encoding.
metrics=[“accuracy”]: Si bien nuestra metrica es accuracy, Keras hará un promedio ponderado del accuracy de cada clase. Este es el comportamiento por defecto.
[ ]:
emdedding_size = 100
[ ]:
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Embedding, Dense, TimeDistributed, LSTM, Input, GRU
[ ]:
# Define an input sequence and process it.
encoder_inputs = Input(shape=(max_seq_len, vocab_size), name="sequence_input")
#embedder = Embedding(input_dim=vocab_size ,input_length=max_seq_len, output_dim=emdedding_size, mask_zero=True)
encoder = LSTM(emdedding_size, return_state=True, name="encoder")
#encoder_embeddings = embedder(encoder_inputs)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(max_seq_len, vocab_size))
#decoder_embeddings = embedder(decoder_inputs)
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(emdedding_size, return_sequences=True, return_state=True, name="decoder")
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(vocab_size, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
2021-09-30 16:58:53.771372: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2021-09-30 16:58:53.775480: E tensorflow/stream_executor/cuda/cuda_driver.cc:313] failed call to cuInit: UNKNOWN ERROR (303)
2021-09-30 16:58:53.776271: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (laptop): /proc/driver/nvidia/version does not exist
2021-09-30 16:58:53.794306: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA
2021-09-30 16:58:54.054306: I tensorflow/core/platform/profile_utils/cpu_utils.cc:102] CPU Frequency: 1497600000 Hz
2021-09-30 16:58:54.057681: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f55b4000b60 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2021-09-30 16:58:54.057701: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2021-09-30 16:58:54.172786: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 15998400 exceeds 10% of free system memory.
2021-09-30 16:58:54.190806: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 15998400 exceeds 10% of free system memory.
2021-09-30 16:58:54.199669: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 15998400 exceeds 10% of free system memory.
2021-09-30 16:58:54.946643: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 15998400 exceeds 10% of free system memory.
2021-09-30 16:58:54.959402: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 15998400 exceeds 10% of free system memory.
Podemos inspeccionar el modelo:
[ ]:
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
sequence_input (InputLayer) [(None, 50, 9999)] 0
__________________________________________________________________________________________________
input_1 (InputLayer) [(None, 50, 9999)] 0
__________________________________________________________________________________________________
encoder (LSTM) [(None, 100), (None, 4040000 sequence_input[0][0]
__________________________________________________________________________________________________
decoder (LSTM) [(None, 50, 100), (N 4040000 input_1[0][0]
encoder[0][1]
encoder[0][2]
__________________________________________________________________________________________________
dense (Dense) (None, 50, 9999) 1009899 decoder[0][0]
==================================================================================================
Total params: 9,089,899
Trainable params: 9,089,899
Non-trainable params: 0
__________________________________________________________________________________________________
sudo apt install graphviz
[ ]:
keras.utils.plot_model(model, show_shapes=True)
Failed to import pydot. You must install pydot and graphviz for `pydotprint` to work.
Entrenamiento
[ ]:
history = model.fit([input_encoder_train, input_decoder_train],
target_decoder_train,
batch_size=124,
epochs=20,
validation_split=0.2)
[ ]:
Entrenamos nuestro modelo
[ ]:
history = model.fit(X_train,
y_train,
batch_size=124,
epochs=20,
validation_data=(X_test, y_test))
Epoch 1/20
21/21 [==============================] - 3s 136ms/step - loss: 1.9097 - accuracy: 0.3610 - val_loss: 1.8371 - val_accuracy: 0.4130
Epoch 2/20
21/21 [==============================] - 2s 116ms/step - loss: 1.6095 - accuracy: 0.5422 - val_loss: 1.3369 - val_accuracy: 0.6498
Epoch 3/20
21/21 [==============================] - 3s 120ms/step - loss: 0.8766 - accuracy: 0.8183 - val_loss: 0.8414 - val_accuracy: 0.8229
Epoch 4/20
21/21 [==============================] - 2s 103ms/step - loss: 0.3740 - accuracy: 0.9576 - val_loss: 0.6677 - val_accuracy: 0.8567
Epoch 5/20
21/21 [==============================] - 2s 118ms/step - loss: 0.1883 - accuracy: 0.9829 - val_loss: 0.6239 - val_accuracy: 0.8663
Epoch 6/20
21/21 [==============================] - 3s 121ms/step - loss: 0.1007 - accuracy: 0.9929 - val_loss: 0.6850 - val_accuracy: 0.8680
Epoch 7/20
21/21 [==============================] - 3s 119ms/step - loss: 0.0683 - accuracy: 0.9933 - val_loss: 0.7685 - val_accuracy: 0.8583
Epoch 8/20
21/21 [==============================] - 2s 113ms/step - loss: 0.0538 - accuracy: 0.9948 - val_loss: 0.6088 - val_accuracy: 0.8784
Epoch 9/20
21/21 [==============================] - 2s 117ms/step - loss: 0.0409 - accuracy: 0.9976 - val_loss: 0.6699 - val_accuracy: 0.8760
Epoch 10/20
21/21 [==============================] - 3s 123ms/step - loss: 0.0331 - accuracy: 0.9984 - val_loss: 0.6897 - val_accuracy: 0.8680
Epoch 11/20
21/21 [==============================] - 2s 118ms/step - loss: 0.0270 - accuracy: 0.9988 - val_loss: 0.7222 - val_accuracy: 0.8688
Epoch 12/20
21/21 [==============================] - 3s 120ms/step - loss: 0.0230 - accuracy: 0.9988 - val_loss: 0.7491 - val_accuracy: 0.8663
Epoch 13/20
21/21 [==============================] - 3s 121ms/step - loss: 0.0206 - accuracy: 0.9988 - val_loss: 0.7233 - val_accuracy: 0.8688
Epoch 14/20
21/21 [==============================] - 2s 114ms/step - loss: 0.0173 - accuracy: 0.9992 - val_loss: 0.7296 - val_accuracy: 0.8712
Epoch 15/20
21/21 [==============================] - 3s 124ms/step - loss: 0.0155 - accuracy: 0.9988 - val_loss: 0.7691 - val_accuracy: 0.8680
Epoch 16/20
21/21 [==============================] - 2s 119ms/step - loss: 0.0158 - accuracy: 0.9988 - val_loss: 0.7888 - val_accuracy: 0.8663
Epoch 17/20
21/21 [==============================] - 2s 116ms/step - loss: 0.0147 - accuracy: 0.9984 - val_loss: 0.7678 - val_accuracy: 0.8655
Epoch 18/20
21/21 [==============================] - 2s 119ms/step - loss: 0.0145 - accuracy: 0.9988 - val_loss: 0.7902 - val_accuracy: 0.8623
Epoch 19/20
21/21 [==============================] - 3s 120ms/step - loss: 0.0158 - accuracy: 0.9980 - val_loss: 0.7454 - val_accuracy: 0.8704
Epoch 20/20
21/21 [==============================] - 3s 120ms/step - loss: 0.0131 - accuracy: 0.9988 - val_loss: 0.7306 - val_accuracy: 0.8736
Evalución de los resultados
Probamos su performance utilizando el test set
[ ]:
predictions = model.predict(X_test).argmax(axis=-1)
[ ]:
from sklearn.metrics import classification_report
print(classification_report(y_test, predictions, target_names=label_encoder.classes_))
precision recall f1-score support
ALIMENTACION 0.93 0.89 0.91 110
AUTOMOCION 0.84 0.89 0.86 148
BANCA 0.92 0.84 0.88 198
BEBIDAS 0.84 0.85 0.84 223
DEPORTES 0.97 0.90 0.93 216
RETAIL 0.85 0.90 0.88 268
TELCO 0.72 0.82 0.77 79
accuracy 0.87 1242
macro avg 0.87 0.87 0.87 1242
weighted avg 0.88 0.87 0.87 1242