Procesamiento de imágenes
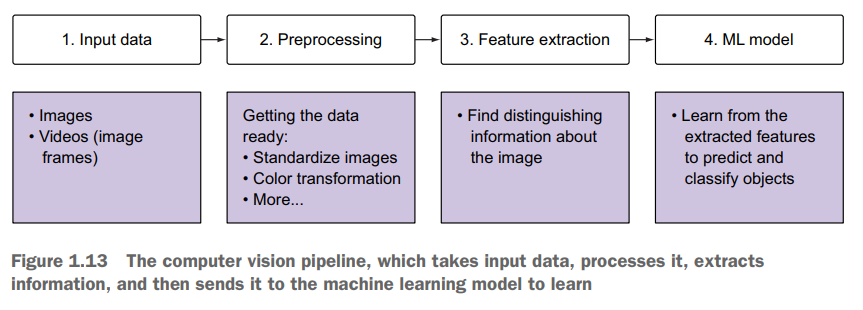
Una aplicación que utiliza las técnicas de visión por computadora en general deberá de implementar una secuencia de pasos que permiten mapear desde las imágenes de entrada hasta la salida que la aplicación necesita. Esta secuencia de pasos se conoce como pipeline. Esta secuencia de pasos puede variar de caso en caso, pero en general siguen la siguiente secuencia:
Imágenes de entrada
Una imágen puede ser representada como una grilla de pixeles, los cuales representan su unidad básica. Estos pixeles representan la intensidad de luz que aparece en un determinado lugar de la imágen. En la versión más sencilla de una imágen, como por ejemplo una fotografía en blanco y negro, los pixeles estarán ordenados en 2 dimensiones x, y o ancho y largo donde cada pixel representa el nivel de luminosidad en cada punto. Este valor de intesidad se representa utilizando un número que va desde 0 a 255 donde 0 es muy oscuro (negro) y 255 es muy claro (blanco). Los valores intermedios representan la escala de grises.
En las imágenes a color, en lugar de representar cada pixel con un solo numero, el mismo se representa utilizando 3 numeros que representan diferentes intensidades dependiendo del sistema de representación. En general, el sistema que mayoritariamente utilizamos es RGB donde cada pixel se representan utilizando 3 números singificando el nivel de intensidad de rojo, de verde y de azul. Existen otros sistemas de representación como HSV (muy utilizado en la web) o Lab.
Imágenes como tensores
Desde el punto de vista de una computadora, las imágenes no son más que un conjunto de intensidades que representan cada uno de los pixeles de la imágen. En general podemos verlas como una matriz de dimensiones ancho x alto de cada imágen. Sin embargo, desde un punto de vista más general podemos pensar en una imágen como un tensor de dimensiones ancho, alto, numero-de-canales. Donde numero-de-canales en general será 1 para una imagen en blanco y negro, y 3 para una imágen en color en formato RGB.
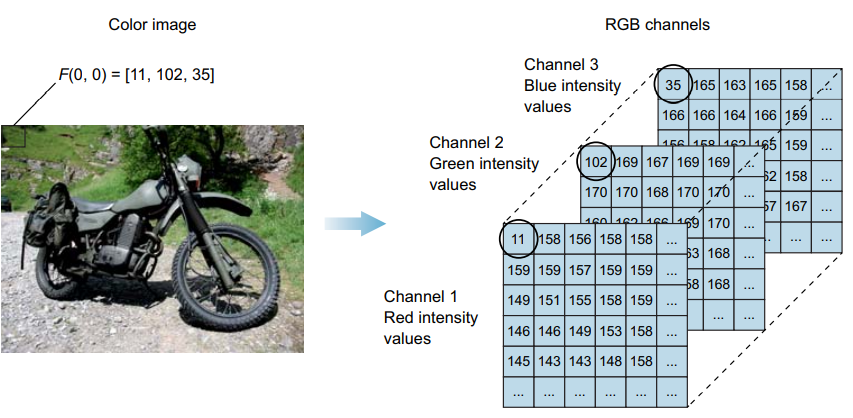
Representación de imagenes en color en RGB
Preprocesamiento
Como análistas o científicos de datos, en general una gran cantidad del tiempo que se invierte en el desarrollo de un modelo de aprendizaje automático está dedicado a la preparación, limpieza y reorganización de los datos. Los sistemas de visión por computadora no son la excepción.
Dependiendo del problema que estamos intentando resolver, será el tipo de preprocesamiento a realizar. Entre la tareas más comunes están:
Estandarización:
Ajuste del tamaño de la imágen a un tamaño estandard.
Recorte de las imágenes.
Ajuste de colores (escala de grises, reducción de contraste, saturación).
Transformaciones específicas como reducciones de ruido.
Aumento o augmentation del conjunto de datos:
Rotaciones.
Translaciones.
Escalamiento.
Modificacione de colores (escala de grises, HUE, saturación, brillo).
Filtros específicos (borronear, ruido).
Combinar imagenes o recortarlas.
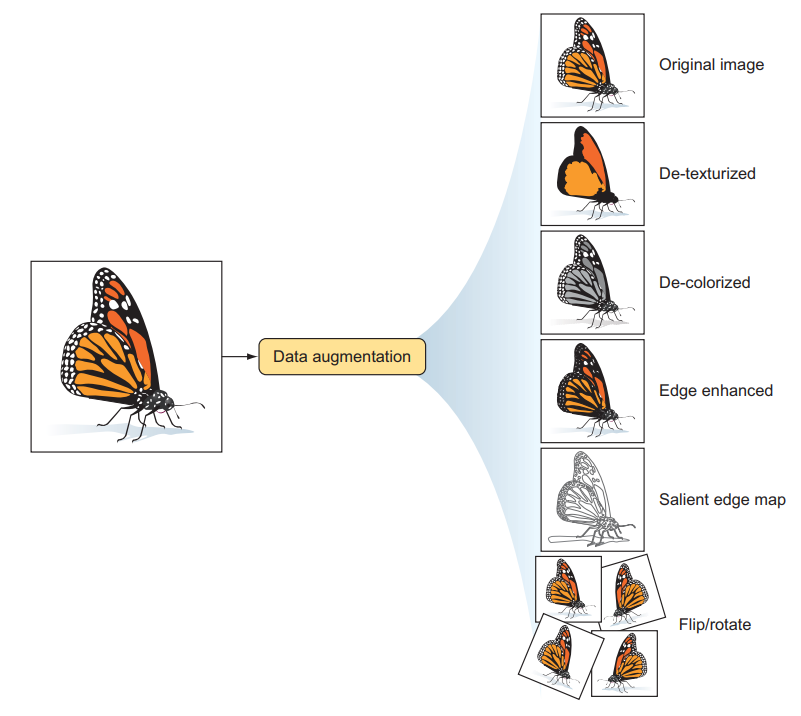
Aumento o augmentation del conjunto de datos
Las tareas de estandarización tiene como objetivo suministrar el modelo de aprendizaje de datos un conjunto más homogeneo o que quizas resalta en mayor medidas los elementos en los que estamos interesados en aprender. Las tareas de aumento del conjunto de datos, por el contrario, tiene como objetivo generar un conjunto de datos más rico y con mayor variabilidad para que nuestro modelo deje de descansar en condiciones especificas de las imágenes que suministramos simplemente porque no tenemos un conjunto de datos lo suficientemente grande.
Ejemplos
Para ver un ejemplo de transformaciones para el aumento del conjunto de datos de entrenamiento puede revisar el ejemplo ../neural/cnn/classification/code/cnn_class_augmentation.ipynb. Sin embargo, el mismo introduce algunos conceptos que se verán más adelante. Refierase solo a la sección de aumento del conjunto de datos utilizando la librería TensorFlow.
Existen otros servicios en la nube, como RoboFlow el cual permite realizar tareas de data augmentation de forma automática.
Extracción de predictores
La extracción de predictores es un componente central de los sistemas de visión por computadora. De hecho, la idea de aprendizaje profundo gira en torno a la idea de aprender cómo extraer características útiles a partir de la imágen para resolver el problema en cuestión.
Aquí la definición de un predictor es un concepto un poco más complicado de ver que en un conjunto de datos estructurado. Un predictor es un dato medible en su imágen que es exclusivo de ese objeto específico. Puede ser un color o una forma específica, como una línea un border, o una curvatura. Estas características deberían de ser util para resolver el problema.
En general buscamos que nuestros predictores tengan propiedades como:
Identificable: que podamos idenficarla cuando se la señala.
Comparable: que dados dos objetos con la caracteristica, podamos comparar que tanto esta presente esta caracteristica en cada imágen
Consistente: que la caracteristica sea consistente independientemente de las condiciones de iluminación de la imágen, ángulo, o posición del objeto.
Visible: que la característica se mantenga presente aunque la imágen esté distorcionada u obstruida por otro objeto.
Existen dos formas de extraer estos predictores: de forma manual o de forma automática (aprenderlos). Nosotros nos centraremos en las técnicas de aprendizaje automática de predictores (deep learning).
Modelo de decisión
El útlimo paso consiste en utilizar un modelo o un estimador para generar las predicciones que necesitamos. Aquí podemos utilizar técnicas de aprendizaje automático tradicionales como SVM o algoritmos basados en redes neuronales profundas. Si bien los algoritmos tradicionales de aprendizaje automático pueden obtener resultados decentes para algunos problemas, las redes neuronales realmente brillan procesando y clasificando imágenes en los problemas más complejos.