|
|
|
Modelos basados en knowledge distillation with no labels (DINO)
PRECAUCIÓN 😱: El tema presentado en esta sección está clasificado como avanzado. El entendimiento de este contenido es totalmente opcional.
Introducción
Las arquitecturas basadas en transformers han acaparado el mundo de NLP y más recientemente emergieron como una alternativa en las tareas de visión por computadora. Los modelos de visión basados en transformers, o ViT - Vision transformers - están inspirados en las tareas de NLP donde estas arquitecturas son preentrenados sobre grandes cantidades de datos y luego, via fine-tuning adaptadas a tareas especificas. Estos modelos son competitivos con respecto a las arquitecturas basadas en CNN, pero aún las mismas no tienen una ventaja especifica hoy en día dado que son más costosos computacionalmente y aún asi no proveen una performance o qualidad superadora a las arquitecturas convolucionales.
Sin embargo, existe una gran diferencia en la forma que los Vision Transfomers son entrenados con respecto a sus homologo para NLP. Mientras ViT se entrena de forma supervisada, gran parte del éxito en los transformers para NLP radica en su entrenamiento self-supervised sobre grandes cantidades de texto.
DINO (Distilation with no labels) es un método para entrenar transformers (aunque se puede aplicar para modelos basados en redes de convolución también) de forma self-supervised (combinado con self-training). DINO fué introducido en el paper Emerging Properties in Self-Supervised Vision Transformers.
Preparación del ambiente
Este notebook require the las siguientes librerias:
[ ]:
%pip install transformers --quiet
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting transformers
Downloading transformers-4.29.1-py3-none-any.whl (7.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.1/7.1 MB 50.5 MB/s eta 0:00:00
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from transformers) (3.12.0)
Collecting huggingface-hub<1.0,>=0.14.1 (from transformers)
Downloading huggingface_hub-0.14.1-py3-none-any.whl (224 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 224.5/224.5 kB 25.4 MB/s eta 0:00:00
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (1.22.4)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers) (23.1)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers) (6.0)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (2022.10.31)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers) (2.27.1)
Collecting tokenizers!=0.11.3,<0.14,>=0.11.1 (from transformers)
Downloading tokenizers-0.13.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (7.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 74.2 MB/s eta 0:00:00
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers) (4.65.0)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (2023.4.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (4.5.0)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2022.12.7)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.4)
Installing collected packages: tokenizers, huggingface-hub, transformers
Successfully installed huggingface-hub-0.14.1 tokenizers-0.13.3 transformers-4.29.1
Idea detras de DINO
DINO está basado en los conceptos de self-training y knowledge distillation.
Self-training
Self-training es una metodología de entrenamiento que busca mejorar la calidad de las features al propagar una pequeña cantidad de anotaciones a un conjunto de datos más grande (que no tiene anotaciones). Esta propagación de las etiquetas puede realizarse asignando un único valor a cada instancia (hard assignment) o asignar una distribución de etiquetas (soft assignment).
Cuando esta asignación se realiza de forma soft, el método se lo conoce como knowledge distillation. En general, esta técnica se utiliza para entrenar a un modelo (pequeño), que se conoce como aprendiz o student, para imitar a un modelo más grande, que se conoce como maestro o teacher, y por ende comprimirlo.
DINO construye sobre esta idea, solo que en lugar de disponer de un modelo teacher, lo remplaza por una modalidad self-supervised.
Arquitectura
El procedimiento es el siguiente.
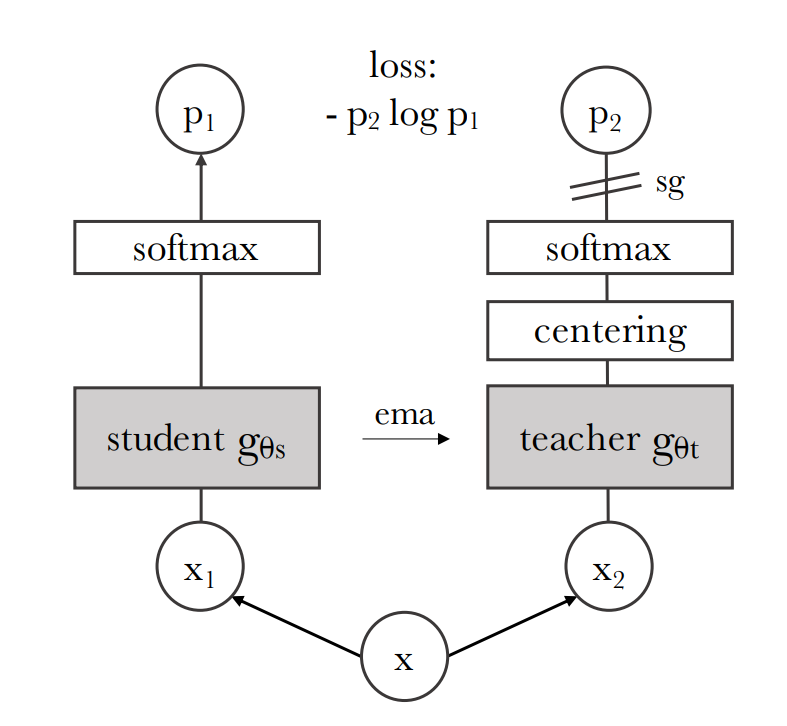
Los modelos teacher y student son 2 redes de igual arquitectura, pero parámetros distintos. Ambos producen predicciones en un espacio dimensional K que es un distribución probabilística (softmax).
En todo momento, el objetivo del modelo student es imitar las predicciones del modelo teacher. Sin embargo, a cada modelo se le suministran datos distintos.
Dada una imagen X, se generan dos subsets de imagenes nuevas, llamadas views.
Un conjunto de global views, que corresponden a recortes de la imágen original que cubren grandes partes de la imágen - más del 50% de la misma.
Un conjungo de local views, que se corresponden a recortes de la imágen original que cubren perqueñas partes de la imágen - menos del 50% de la misma.
Las imágenes del conjunto de local views son suministradas solo al modelo student, mientras que las global views son suministradas al modelo teacher. Sin embargo, la función de perdida con la que entrenamos al modelo student lo fuerza a producir predicciones similares al modelo teacher. De esta manera, el modelo student es incentivado a aprender mapeos que vayan desde predictores locales a globales.
En cada iteración, solo los parámetros del modelo student son actualizados, mientras que los del modelo teacher se mantienen constantes.
Para que esta configuración de entrenamiento converja, al final de cada iteración, los parámetros del modelo student son copiados (o transfeidos - en realidad se utiliza un exponential moving average) al modelo teacher. Es decir, que el modelo teacher siempre es una instancia anterior del modelo student.
Utilizando las representaciones de DINO
Veamos como podemos utilizar DINO en un ejemplo.
Descarguemos una imagen de ejemplo:
[ ]:
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
[ ]:
image

El modelo puede descargarse desde HuggingFace utilizando el siguiente nombre:
[ ]:
model_name = 'facebook/dino-vitb16'
Luego, como es costumbre, utilizaremos transformers para cargar el modelo y ejecutarlo:
[ ]:
from transformers import ViTImageProcessor, ViTModel
feature_extractor = ViTImageProcessor.from_pretrained(model_name)
model = ViTModel.from_pretrained(model_name)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
Some weights of ViTModel were not initialized from the model checkpoint at facebook/dino-vitb16 and are newly initialized: ['pooler.dense.weight', 'pooler.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Podemos verificar las dimensiones de estos embeddings:
[ ]:
last_hidden_states.shape
torch.Size([1, 197, 768])
De igual forma que hicimos anteriormente, podemos utilizar ViTForImageClassification para agregar una capa lineal a la salida del token [CLS] que el modelo preentrenado genera. El último hidden state de este token puede considerarse como una representación del total de imagen:
[ ]:
from transformers import ViTForImageClassification