|
|
|
Explicaciones para NLP utilizando LIME
Introducción
LIME es una novedosa técnica de explicación que explica las predicciones de cualquier clasificador de manera interpretable al aprendiendo un modelo interpretable localmente alrededor de la predicción que el modelo verdadero realiza. Es decir, LIME construye un modelo (interpretable) alrededor de esta predicción con el objetivo de poder comprender como se comporta el espacio (manifold) en esa región confinada. La idea es que si bien un modelo interpretable puede tener muy mala correlación sobre todo el conjunto de datos, puede tener una muy buena correlación en una zona acotada del espacio.
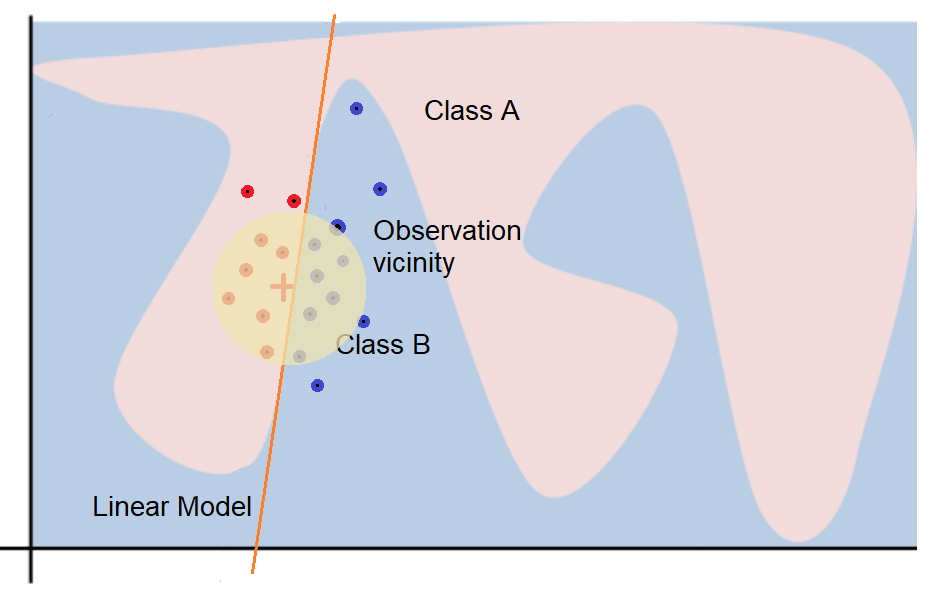
Este método resulta flexible explicando diferentes modelos de texto y clasificación de imágenes ya que se los puede extender a estos dominios (haciendo algunas salvedades).
Para una introducción más detallada puede ver la entrada del blog: Model interpretability — Making your model confesses: LIME
¿Como se computa el modelo local que entrena lime?
Para aprender el comportamiento local del modelo (función f), LIME aproxima la función f* en las instancias que están cerca de la instancia que queremos explicar. Estas instancias son generadas (muestreadas) y luego poderadas según que tan lejos están de la instancia que necesitamos explicar.
En el caso del texto, estas muestras son generadas eliminando de forma aleatoria palabras de la observación original. Si el modelo descansaba en esta palabra, entonces el mismo debería ver una caida en la performance notable. Adicionalmente, mencionamos que esta perdida estaba poderada por «que tan parecida o no» es la muestra a la observación original, es decir que necesitamos una métrica de similaridad. En el caso de texto, esta metrica es la similaridad del coseno, que mide el ángulo de diferencia entre dos vectores.
Note aqui que los modelos que aprenden representaciones de forma interna no tienen una injerencia en esta métrica de similaridad.
Para ejecutar este notebook
Para ejecutar este notebook, instale las siguientes librerias:
[ ]:
!wget https://raw.githubusercontent.com/santiagxf/M72109/master/NLP/Datasets/mascorpus/tweets_marketing.csv \
--quiet --no-clobber --directory-prefix ./Datasets/mascorpus/
[16]:
!pip install transformers --quiet
!pip install lime --quiet
!pip install eli5 --quiet
Descargaremos un modelo previamente entrenando el el problema de clasificación de Tweets:
[ ]:
!wget https://santiagxf.blob.core.windows.net/public/models/tweet_classification_bert.zip --no-clobber --quiet
!unzip -qq tweet_classification_bert.zip
[ ]:
import warnings
warnings.filterwarnings('ignore')
Cargamos el conjunto de datos con el que se entrenó el modelo en caso de necesitarlo
[ ]:
import pandas as pd
tweets = pd.read_csv('Datasets/mascorpus/tweets_marketing.csv')
Cargando un modelo de NLP
Cargaremos el modelo que fue descargado anteriornmente utilizando la librería de transformers. Note que cargamos tanto el tokenizer como el modelo propiamente dicho.
[ ]:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "tweet_classification_bert"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
Entrenando el modelo de LIME
Función de predicciones
Para poder utilizar el método de LIME es necesario implementar una función que reciba como entrada un texto y devuelva la distribución probabilistica de las diferentes etiquetas que nuestro modelo predice. La función que sigue realiza esto:
[ ]:
import torch
import numpy as np
from typing import Union, List
def predict_proba(text: Union[str, List[str]]) -> np.ndarray:
"""
Ejecuta el modelo sobre una secuencia de texto arbitraria y devuelve la distribución probabilistica para cada una de las clases.
Parameters
----------
text: Union[str, List[str]]
Texto sobre el que se desea ejecutar el modelo
Returns
-------
np.ndarray
Distribución probabilistica de las clases del modelo.
"""
inputs = tokenizer(text, padding=True, truncation=True, max_length=20, return_tensors='pt')
predictions = model(**inputs)
smx = torch.nn.Softmax(dim = 1)(predictions.logits)
return smx.detach().numpy()
Verifiquemos que la función funciona
[ ]:
predict_proba(["la casa estaba si vacia claro"])
array([[0.4471247 , 0.02632283, 0.03702476, 0.08742985, 0.04531398,
0.318541 , 0.03824287]], dtype=float32)
Recordemos que nuestro modelo predice los sectores a los que pertenecería el tweet, siendo ellos:
[ ]:
target_names = ['ALIMENTACION', 'AUTOMOCION', 'BANCA', 'BEBIDAS', 'DEPORTES', 'RETAIL', 'TELCO']
Entrenando el modelo localmente en la instancia a explicar
[ ]:
from eli5.lime import TextExplainer
te = TextExplainer(random_state=42, n_samples=500).fit("Nos estafaron en carrefour. No vuelvo a comprar alli jamas", predict_proba)
Veamos las explicaciones:
[ ]:
te.show_prediction(target_names=target_names)
y=ALIMENTACION (probability 0.016, score -4.122) top features
| Contribution? | Feature |
|---|---|
| -0.134 | <BIAS> |
| -3.988 | Highlighted in text (sum) |
nos estafaron en carrefour. no vuelvo a comprar alli jamas
y=AUTOMOCION (probability 0.023, score -3.706) top features
| Contribution? | Feature |
|---|---|
| -0.578 | <BIAS> |
| -3.128 | Highlighted in text (sum) |
nos estafaron en carrefour. no vuelvo a comprar alli jamas
y=BANCA (probability 0.038, score -3.213) top features
| Contribution? | Feature |
|---|---|
| -0.564 | <BIAS> |
| -2.649 | Highlighted in text (sum) |
nos estafaron en carrefour. no vuelvo a comprar alli jamas
y=BEBIDAS (probability 0.013, score -4.269) top features
| Contribution? | Feature |
|---|---|
| -0.534 | <BIAS> |
| -3.735 | Highlighted in text (sum) |
nos estafaron en carrefour. no vuelvo a comprar alli jamas
y=DEPORTES (probability 0.015, score -4.166) top features
| Contribution? | Feature |
|---|---|
| -0.599 | <BIAS> |
| -3.567 | Highlighted in text (sum) |
nos estafaron en carrefour. no vuelvo a comprar alli jamas
y=RETAIL (probability 0.880, score 2.249) top features
| Contribution? | Feature |
|---|---|
| +2.635 | Highlighted in text (sum) |
| -0.386 | <BIAS> |
nos estafaron en carrefour. no vuelvo a comprar alli jamas
y=TELCO (probability 0.015, score -4.165) top features
| Contribution? | Feature |
|---|---|
| -0.624 | <BIAS> |
| -3.541 | Highlighted in text (sum) |
nos estafaron en carrefour. no vuelvo a comprar alli jamas
La utilización de estas explicaciones hace sentido: esperamos que un clasificador razonable tenga en cuenta las palabras resaltadas. Pero, ¿cómo podemos estar seguros de que así es como funciona el modelo? Una simple verificación es eliminar o cambiar las palabras resaltadas, para confirmar que cambian el resultado: